 超算云
超算云 AI智算云
AI智算云在北京超算V100-32G顯卡上跑WRF是一種怎樣的體驗(yàn)?
在北京超算GPU上跑WRF是一種怎
1WRF on GPU?YES!
WRF是在美國(guó)國(guó)家大氣研究中心(NCAR)開(kāi)發(fā)的天氣研究和預(yù)報(bào)模型。它被162個(gè)國(guó)家的36000多個(gè)注冊(cè)用戶(hù)廣泛使用。WRF具有多個(gè)動(dòng)態(tài)核心,支持大規(guī)模并行計(jì)算,且系統(tǒng)可擴(kuò)展性很強(qiáng)。WRF 適用于從米到數(shù)千公里的廣泛應(yīng)用。它是氣象學(xué)科中最為廣泛使用的數(shù)值模式之一。
熟悉WRF模式的小伙伴都知道,WRF是在CPU上運(yùn)行的。而隨著高性能計(jì)算技術(shù),特別是使用圖形處理器(GPU)等硬件進(jìn)行大規(guī)模并行計(jì)算的技術(shù)正在日漸成熟,并在人工智能等領(lǐng)域不斷長(zhǎng)足發(fā)展。
那么,既然WRF如此適合大規(guī)模并行計(jì)算,那么,我們可以在GPU上運(yùn)行WRF,以達(dá)到減低成本、增加效率的效果嗎?答案當(dāng)然是YES。
2AceCast: WRF的GPU版本
AceCast是美國(guó)TempoQuest (TQI)公司開(kāi)發(fā)的軟件產(chǎn)品。其前身為英偉達(dá)公司支持開(kāi)發(fā)的WRF-G。它由GPU提供支持,可以加速WRF模型。AceCAST 是五年來(lái)一絲不茍的研究和開(kāi)發(fā)的產(chǎn)物,它使得 WRF 用戶(hù)能夠利用 GPU 硬件與傳統(tǒng) CPU 計(jì)算的高度并行性來(lái)保證優(yōu)化性能。AceCAST 包含了大量重構(gòu)的通用 WRF 物理、動(dòng)力學(xué)模塊和namelist,它使用了NVIDIA CUDA 或 OpenACC GPU編程技術(shù),允許廣大用戶(hù)幾乎不需要改變?nèi)魏闻渲茫湍軐ceCAST作為現(xiàn)有WRF的平替,并加以使用。
GPU通過(guò)使用具有高速計(jì)算速度和非常高的內(nèi)存帶寬的多線程、多核處理器來(lái)實(shí)現(xiàn)異常的加速。通用超級(jí)計(jì)算、高并行性、高內(nèi)存帶寬、低成本和緊湊體積的綜合特性使得基于 gpu 的系統(tǒng)成為由普通 CPU 集群組成的大規(guī)模并行處理機(jī)/計(jì)算機(jī)系統(tǒng)的一個(gè)有吸引力的替代品。基于 GPU 開(kāi)發(fā)的WRF 是目前世界上最快、分辨率最高的天氣預(yù)報(bào)模型。
TempoQuest 通過(guò)利用GPU加速 WRF 模型解決了這個(gè)問(wèn)題。與標(biāo)準(zhǔn)的計(jì)算方法相比,AceCAST 是目前世界上最快和分辨率最高的天氣預(yù)報(bào)模型。通過(guò) AceCAST 運(yùn)行 WRF,使用戶(hù)能夠以更高的分辨率、更低的成本和更深的洞察力運(yùn)行預(yù)測(cè)和研究模擬,并加速解決時(shí)間流程。AceCAST 的能力為氣象學(xué)家和最終用戶(hù)提供了 WRF 產(chǎn)品,這些產(chǎn)品能夠提高對(duì)全球氣象模型無(wú)法識(shí)別或在低分辨率情況下無(wú)法識(shí)別的局部天氣現(xiàn)象的認(rèn)識(shí)。計(jì)算性能的提高使得高分辨率的確定性和概率性預(yù)報(bào)成為可能,而且比在中央處理器上運(yùn)行 WRF 成本更低,預(yù)報(bào)模擬加速度一致地將預(yù)報(bào)處理速度提高了5倍。
3AceCast實(shí)戰(zhàn)測(cè)試
為了準(zhǔn)確評(píng)估比較WRF在GPU和CPU上的運(yùn)行速度,我和北京超算團(tuán)隊(duì)一起,使用北京超算提供的8卡V100-32G顯卡資源,對(duì)一個(gè)800×600×33,單層嵌套的個(gè)例進(jìn)行模擬。分別進(jìn)行了1卡、2卡、4卡和8卡四個(gè)實(shí)驗(yàn),主要計(jì)算其運(yùn)行效率。實(shí)驗(yàn)結(jié)果如下:
GPU個(gè)數(shù) | 運(yùn)行時(shí)間 |
1 | 約21分鐘 |
2 | 約12分鐘 |
4 | 約7分20秒 |
8 | 約5分鐘 |
4對(duì)比:CPU上運(yùn)行WRF的效率
CPU節(jié)點(diǎn)數(shù) | 運(yùn)行時(shí)間 |
1 | 30分51秒 |
2 | 16分9秒 |
4 | 9分33秒 |
8 | 6分31秒 |
5對(duì)比:性能和價(jià)格
在北京超算上,一張V100-32G顯卡的價(jià)格約為5元/小時(shí)(價(jià)格根據(jù)用戶(hù)合同和使用時(shí)間等因素不同,會(huì)有所波動(dòng),下同。);一個(gè)CPU核心的價(jià)格約為0.1元/小時(shí)。由此可以估算出,這次試驗(yàn)的消費(fèi)金額(單精度CPU節(jié)點(diǎn)以40%提速預(yù)計(jì),未進(jìn)行實(shí)地實(shí)驗(yàn)):
設(shè)備 | 運(yùn)行時(shí)間 | 理論價(jià)格(元) |
CPU*1節(jié)點(diǎn) | 30分51秒 | 3.29 |
CPU*2節(jié)點(diǎn) | 16分9秒 | 3.44 |
CPU*4節(jié)點(diǎn) | 9分33秒 | 4.07 |
CPU*8節(jié)點(diǎn) | 6分31秒 | 5.56 |
單精度CPU*1節(jié)點(diǎn) | 22分2秒 | 2.35 |
單精度CPU*2節(jié)點(diǎn) | 11分32秒 | 2.46 |
單精度CPU*4節(jié)點(diǎn) | 6分49秒 | 2.91 |
單精度CPU*8節(jié)點(diǎn) | 4分39秒 | 3.97 |
GPU*1卡 | 21分鐘 | 1.75 |
GPU*2卡 | 12分鐘 | 2.00 |
GPU*4卡 | 7分20秒 | 2.44 |
GPU*8卡 | 5分鐘 | 3.33 |
6總結(jié)與討論
由表格我們可以得出以下結(jié)論:
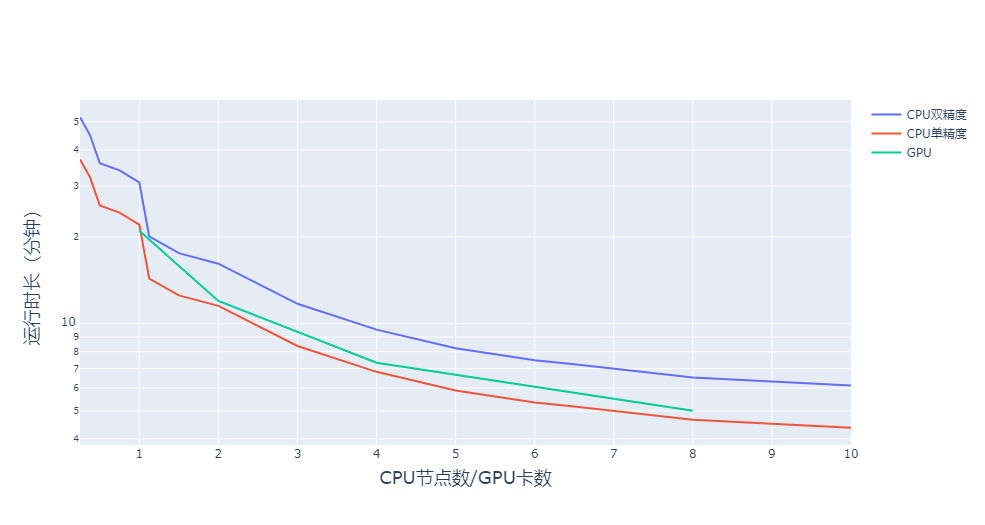
使用單卡GPU的性?xún)r(jià)比最高,約比CPU上單精度計(jì)算便宜25%,比傳統(tǒng)的雙精度便宜50%左右;
就速度而言,在CPU(單精度)使用不超過(guò)2個(gè)節(jié)點(diǎn)時(shí),使用GPU也比CPU要快(不考慮輻射參數(shù)化方案的影響的前提下;考慮的話(huà),相信速度提升會(huì)更明顯)。考慮到我們一般模擬任務(wù)不太會(huì)超過(guò)800×600×33,可見(jiàn)使用GPU,不管是時(shí)間還是金錢(qián)成本上,肯定都是優(yōu)于CPU的;
GPU運(yùn)行速度隨著卡數(shù)的上升,并非是線性提高的。具體如下圖所示:
本次采用的GPU為V100-32G。其單精度浮點(diǎn)運(yùn)算性能14TFlops;而如果我們采用單精度浮點(diǎn)運(yùn)算性能更高、價(jià)格卻更加便宜的3090顯卡(35.7TFlpos),相信GPU的優(yōu)勢(shì)可以變得更為明顯。
總結(jié)一句話(huà):要是WRF規(guī)模不太大,直接上單卡3090!性?xún)r(jià)比最高,最省時(shí)間!
7參考文獻(xiàn)
FV3 (2017): www.gfdl.noaa.gov/fv3/fv3-performance
Váňa et al (2017) "Single Precision in Weather Forecasting Models: An
Evaluation with the IFS" Mon. Wea. Rev., Vol. 145, No. 2. (7 December 2016),
pp. 495-502, doi:10.1175/mwr-d-16-0228.
北京超算GPU算力資源
A100V1003090A10T4國(guó)產(chǎn)DCU等多種型號(hào);提供云主機(jī)、集群、裸金屬云服務(wù)等多種算力平臺(tái);支持多機(jī)多卡,滿(mǎn)足訓(xùn)練、推理、科學(xué)計(jì)算等多計(jì)算場(chǎng)景需求。讓GPU算力觸手可及,省事省心,高效專(zhuān)注科研!
掃碼免費(fèi)領(lǐng)取2000核時(shí)或200元卡時(shí)計(jì)算資源!







